
Linear barcode is also known as 1D barcode and is used to store data in one dimension only. There are many types of linear barcodes.
There are many types of linear barcodes, some of which are described below:

Codabar is linear barcode, developed in 1972 by Pitney Bowes Corp. It is also known as Codeabar, Rationalized Codabar, Monarch, Code 2 of 7, Ames Code, NW-7, USD-4 and ANSI/AIM BC3-1995.
Often used in libraries, blood banks, parcels and more.
Codabar is 1D barcode symbology developed in 1972 by Pitney Browse Corp. Codabarcode is also known as Codeabar, Ames Code, NW-7, Monarch, Code 2 of 7, Rationalized Codabar, ANSI/AIM BC3-1995 or USD-4. Codabar is discrete self checking barcode symbology that can encode 16 different characters and additional 4 start/stop characters. Because codabar barcode is self checking most standard does not define check digit. Originally Codabar barcode was used in FedEX airbills and blood bank forms. Although the newer barcode symbologies hold more data in a smaller place.
In Codabar barcode each character contains 7 elements, 4 bars and 3 spaces that are separated from its adjacent characters by an additional narrow space. Each can be either narrow (Binary value 0) or wide (Binary value 1).
The original Pitney-Bowes specification actually varies the narrow: wide width ratio to make all characters the same width. That is, characters with 2 wide elements use a 3:1 ratio, while characters with 3 wide elements use a 2:1 ratio, so all characters are 10 narrow elements wide (plus the inter-character space makes 11). "Rationalized codabar" uses a fixed ratio and allows the character widths to vary.
In Codabar barcode the characters are divided into three groups based upon the numbers of elements:
- The basic 12 symbols (digits 0-9, dash and $) are encoded using all possible combinations of one wide bar and one wide space.
- An additional 4 symbols (+ :/.) are encoded using 3 wide bars and no wide spaces.
- 4 start/stop symbols (ABCD, or EN*T) are encoded using one wide bar and two wide spaces.

Code 11 barcode symbology can encode string of any length that consists of digit (0-9) and dash character (-). Code 11 barcode is primarily used to label telecommunication equipments.
Primarily for labeling telecommunications equipment.
Code 11 is a type of linear barcode symbology, developed by Intermec in 1977. It is primarily used to label telecommunication equipment. The character set of Code 11 barcode includes digits (0-9), a dash character (-) and stop/start code. Each character is encoded with three bars and two spaces. In these five elements, two of which are wide and the remaining three are narrow or one wide element and four narrow element.
Code 11 is discrete and high density barcode that contain only digits and the - symbol. This barcode symbology used with one or two Mod 11 check characters. The dash (-) symbol is used when the check character value is 10. In Code 11 barcode, wide elements represent binary 1 while the narrow elements represent binary 0. Code 11 is high density, numeric barcode symbology. Code 11 uses one or two weighted checksum digits (C and K). If the length of the encoded data is less than 10 characters then ‘C’ digit is used, otherwise both of the weighted checksum digits i.e. 'C' and 'K' are used if the encoded data is 10 characters or long.
Code 11 barcode can encode string of any length consisting of digits 0-9 and the dash character. This barcode symbology contains one or more modulo 11 check digits. In Code 11 barcode each character is represented by standalone group of three bars and two spaces. This barcode symbology is not self checking.
Code 11 barcode is also known as USD-8. In Code 11 barcode the characters are separated by an inter character gap which has same width as narrow element. The structure of Code 11 barcode includes a start character, data encoded, "C" check digit, “K" check digit (if the length of encoded data is greater than 10) and a stop character.

Code 128 is one of the most widely used linear barcode symbology that encodes full 128-character ASCII character set and extended character sets.
Used in shipping and packaging industries.
Code 128 is high density barcode symbology which allows the encoding of alphanumeric data. Code 128 barcodes provide facility to encode 128 characters of ASCII. This barcode symbology contains a checksum digit for verification and the barcodes can be verified character by character. Code 128 barcode has been word wide used in shipping and packaging industries for product identification.
Code 128 barcode has been widely implemented in various applications where large amount of data must be encoded. Code 128 barcode includes 0-9 digits, A-Z letters and all standard ASCII Symbols and control code. Code 128 is divided into three subset A, B and C.
128A (Code 128 Set A): Code 128 Set A includes the standard ASCII symbols, digits, upper case letters and control codes (ASCII Characters 00 to 95, 0-9, A-Z and control codes, special characters and FNC 1-4).
128B (Code 128 Set B): Code 128 Set B includes standard ASCII symbols, digits, upper and lower case letters (ASCII characters 32 to 127, 0-9, A-Z, a-z, Special characters and FNC 1-4).
128C (Code 128 Set C): Code 128 Set C compresses two numeric digits into each character, providing excellent density (00-99, encode each to digits with one code and FNC 1-4).
Structure of 128-barcode:
Quit zone
The quit zone should be at least ten times the width of narrowest bar/space element. It is mandatory at the left and right side of the barcode. The quit zone must not be less than 6.4 mm wide.
Start/stop and encoded data
Each character in Code 128 barcode is composed of three bars and three spaces. Each bar or space is 1, 2, 3 or 4 unit wide, the sum of the width of the bars must be even, the sum of width of spaces must be odd and total 11 unit per character. For instance, encoding the ASCII value 0 can be viewed as 10011101100 where a 1 (one) is a bar and a 0 is space. A combination which contains a single 1 would be thinnest line in barcode. A combination including three 1 (111) in sequence indicates a bar three times as thick as single bar.

Code 11 barcode symbology can encode string of any length that consists of digit (0-9) and dash character (-). Code 11 barcode is primarily used to label telecommunication equipments.
Used for inventory and tracking purpose.
Code 128 is high density barcode symbology which allows the encoding of alphanumeric data. Code 128 barcodes provide facility to encode 128 characters of ASCII. This barcode symbology contains a checksum digit for verification and the barcodes can be verified character by character. Code 128 barcode has been word wide used in shipping and packaging industries for product identification.
Code 128 barcode has been widely implemented in various applications where large amount of data must be encoded. Code 128 barcode includes 0-9 digits, A-Z letters and all standard ASCII Symbols and control code. Code 128 is divided into three subset A, B and C.

Code 128 set B barcode is used for alphanumeric data including uppercase letters, lowercase letters, numbers (0-9) and punctuation marks.
Most likely used in inventory and shipping field.
Code 128 is high density barcode symbology which allows the encoding of alphanumeric data. Code 128 barcodes provide facility to encode 128 characters of ASCII. This barcode symbology contains a checksum digit for verification and the barcodes can be verified character by character. Code 128 barcode has been word wide used in shipping and packaging industries for product identification.
Code 128 barcode has been widely implemented in various applications where large amount of data must be encoded. Code 128 barcode includes 0-9 digits, A-Z letters and all standard ASCII Symbols and control code. Code 128 is divided into three subset A, B and C.

Code 128 set C barcode is numeric only barcode. Code set C symbols can only contain numbers, never letters. Code 128 set C symbols are narrower than code 128 set A and code 128 set B barcodes.
Used in shipping, industry and inventory field.
Code 128 is high density barcode symbology which allows the encoding of alphanumeric data. Code 128 barcodes provide facility to encode 128 characters of ASCII. This barcode symbology contains a checksum digit for verification and the barcodes can be verified character by character. Code 128 barcode has been word wide used in shipping and packaging industries for product identification.
Code 128 barcode has been widely implemented in various applications where large amount of data must be encoded. Code 128 barcode includes 0-9 digits, A-Z letters and all standard ASCII Symbols and control code. Code 128 is divided into three subset A, B and C.

Code 39, barcode is discrete, variable length and alphanumeric barcode symbology that is specially used in non retail environments.
Used for various labels such as name badges, inventory and industry.
Code 39 barcode was developed by Dr. David Allais and Ray Stevens of Intermec in 1974. Their original design included two wide bars and one wide space in each character, resulting in 40 possible characters. Setting aside one of these characters as a start and stop pattern left 39 characters, which was the origin of the name Code 39. Punctuation characters were later added that deviated from this pattern, expanding the character set to 43 characters.
Code 39 was later standardized as ANSI MH 10.8 M-1983 and MIL-STD-1189. MIL-STD-1189 has been cancelled and replaced by ANSI/AIM BC1/1995, Uniform Symbology Specification. Code 39 (also known as Code 3 of 9, Alpha39, Code 3/9, Type 39, USS Code 39, or USD-3) is a variable length, 1D discrete barcode symbology. Code 39 is first alpha-numeric one dimesional barcode symbology to be developed. It is the standard barcode used by the United States Department of Defence and is also used by the Health Industry BarCode Council.
Code 39 barcodes define 43 characters, consists uppercase letters (A through Z), numeric digits (0 through 9) and a number of special characters (-, ., $, /, +, %, and space). An additional character (denoted '*') is used for both start and stop delimiters. Each character is composed of nine elements: five bars and four spaces. Three of the nine elements in each character are wide (binary value 1) and six elements are narrow (binary value 0).
The major advantage of Code 39 barcode is that since there is no need to generate a check digit, it can be integrated into existing printing system by adding a barcode font to the system or printer and then printing the raw data in that font. The most serious drawback of Code 39 is its low data density, It requires more space to encode data in Code 39 than, for example, in Code 128. This means that very small products cannot be labeled with a Code 39 barcodes. However, Code 39 is still widely used and can be decoded with virtually any barcode reader.

Code 93 is variable length and continuous barcode symbology that represents full ASCII character set. Code 93 is used in Canadian postal office to encode supplementary delivery information.
Primarily used in postal services.
Code 93 barcode was developed to improve code 39. Code 93 barcode symbology was designed in 1982 by Intermec. It is an alphanumeric, variable length 1D barcode symbology that provides higher density and more data security enhancement to Code 39 barcode. Code 93 is primarily used by Canada post to encode supplementary delivery information. Every barcode symbol includes two check characters. In addition to 43 characters, Code 93 barcoding system defines 5 special characters (including a start/stop character), which can be combined with other characters to represent full 128 ASCII characters.
In Code 93 barcode each character is divided into nine modules and has three bars and three spaces. Each bar and space is from 1 to 4 modules wide. In Code 93 barcode the minimum value of X dimension is 7.5 mils (0.19 mm), the minimum height is 15 percent of the symbol length or 0.25 inches (6.35 mm). The starting and trailing quiet zone should be at least 0.25 inches (6.35 mm).
What kind of data can be encoded by Code 93?
- The Standard Mode (Default implementation) can encode uppercase letters (A through Z), digits (0 through 9) and special characters (*, -, $, %, (Space), ., /, and + ).
- The Full ASCII Mode or Extended Version can encode all 128 ASCII characters.
A typical Code 93 barcode has the following structure:
- A start character *
- Encoded message
- First modulo-47 check character "C"
- Second modulo-47 check character "K"
- Stop Character *
- Termination bar

Full ASCII Code 39 barcode (also known as Extended Code 39 barcode) is linear barcode symbology that encodes the lower 128 ASCII characters using pairs of Code 39 characters.
Widely used in industry.
Code 39 full ASCII barcode is general purpose 1D discrete barcode symbology that can encode any ASCII characters. This barcode symbology contains the 43 character set, a start and stop character. Code 39 full ASCII barcode can encode standard characters as well as the ASCII control characters. Code 39 full ASCII is linear barcode symbology Code 39 Full ASCII can encode all 128 standard ASCII values using three digits ASCII code, preceded by the \ character.
Code 39 full ASCII barcode is also known as Extended Code 39. Code 39 full ASCII is one dimensional barcode that contains the additional characters by combining two regular Code 39 characters. This barcode symbology is mainly used in military, manufacturing and health sectors.
Code 39 full ASCII barcodes encode all 128 ASCII character set. Code 39 full ASCII barcode symbology uses the four characters such as “$”, “/”, “+”, “%”. Since the Code-39 full ASCII barcodes use shift characters in combination with other standard characters to represent data, so each non standard character requires twice width of standard characters that are printed in barcode symbol. Code 39 Full ASCII is variants of Code39 barcode symbology that encodes all 128 characters in the ASCII table.
Code 39 Full ASCII barcode has the following structure:
- Start Character (*)
- Encoded data
- Check digit
- Stop character (*)

EAN13 barcode in one of the most popular linear barcode symbology that encodes 12 digits of numeric data along with a trailing check digit, total of 13 digits of barcode data.
Retail product marking world-wide.
EAN stands for European Article Number. EAN13 is 13 digit barcode symbology that is designed by the International Article Numbering Association (EAN) in Europe. It is an extension to UPCA barcode. The only difference between UPCA and EAN13 barcode is that the number system of UPCA is single digit from 0 through 9 whereas an EAN13 number system consists of two digits ranging form 00 to 99 which is essentially a country code.
EAN13 is 1D barcode symbology that encodes 13 digits of data (12 digits of numeric data and a trailing check digit). EAN13 barcode is useful for marking products that are sold in retail POS. EAN13 code is superset of UPCA barcode, so that any hardware or software is capable to read EAN13 symbol will also able to read UPCA barcode.
EAN barcode contains the following of four parts:
- 2-3 digit number system or country code
- 5-4 digit Manufacturer Code
- 5 digits product code
- 1 check digit
Within the EAN code the number system digit is printed to the left of the barcode and check digit to right of the EAN codes. The manufacturer and product codes are printed below of the barcodes and separated by guard bar.
EAN13 barcodes encode 13 characters, the first two or three digits represent the country code which identify the particular country in which the manufacturer is registered. The country code is followed by 9 or 10 data digits (usually depend upon the length of country code).

EAN8 barcode is short version of EAN13 barcode. EAN8 barcode is used on small packages where an EAN13 barcode would be large.
Retail product marking world-wide with limited label space.
EAN8 barcode is derived from the EAN13 (European Article Number). EAN8 barcode includes 2 or 3 digit country code, 4 of 5 data digits (depending on the length of the country code), and a checksum digit. While it is possible to add a 2-digit or 5-digit extension barcodes, the main purpose of the EAN8 code is to use as little space as possible. EAN8 barcode was developed for use on small packages where EAN13 barcode would be too large for examples cigarettes, pencils, chewing gum packets and other products.
Unlike the UPCE symbol, which compresses data that could also be printed as a full-size UPCA symbol by squeezing out zeroes, the data digits in an EAN8 symbol specifically identify a particular product and manufacturer. Since a limited number of EAN8 barcodes are available in each country, they are issued only for products with insufficient space for a normal EAN13 symbol. For example, 2-digit country code permits total of only 100,000 item numbers.
EAN8 is 1D barcoding system that consists 7 digits of messages plus 1 check digit. The first two or three digits identify the numbering authority. The remaining 4 or 5 identify the product.
EAN8 barcode has following structure:
- Left- hand guard bars, or starts sentinel encoded as 101.
- Two number system characters, encoded as left-hand odd parity characters.
- First two message characters, encoded as left-hand odd-parity characters.
- Center guard bars encoded as 01010.
- Last three message characters, encoded as right-hand characters.
- Check digit, encoded as right-hand character.
- Right-hand guard or end sentinel encoded as 101.

Industrial 2 of 5 is low density numeric barcode symbology developed in 1970s. This symbology is called "2 of 5" due to the fact that it consists of 2 thick and 3 thin bars out of total 5 bars.
Used on any computer system.
Industrial 2 of 5 is numeric and low density linear barcode symbology that was invented in 1960, at Identicon Corp. Industrial 2 of 5 barcode is also known as Code 2/5, 2 of 5, C 2 of 5, 2 of 5 Standard, 2/5 Standard, 2 of 5 Industrial etc. This barcode symbology contains of 0-9 digits, start and stop character. It is called industrial 2 of 5 because it contains five bars in which two bars are wide and three bars are narrow and space is predefined to separate the bars. This bar coding system uses bar width to encode the data.
Industrial 2 of 5 is one dimensional barcoding system that is used to encode digits only. This 1D barcode symbology is self checking and does not hold any checksum.
Character set of industrial 2 of 5 barcode:
- Numbers (0-9)
- Start Character
- Stop Character
Since the Industrial 2 of 5 is low density barcode symbology. In the industrial 2 of 5 code the barcode data is encoded in the bars, whereas the spaces are fixed width and used to separate the bars. This barcode symbology is self checking and does not include checksum. Industrial 2 of 5 barcodes encode data within the width of the bars. The spaces in the barcodes are only used to separate the bars.
Areas of Application:
- A start character *
- Photofinishin
- Warehousing industry
- Distribution Industry
- Airline tickets etc.

Interleaved 2 of 5 is high density and numeric linear barcode symbology that encodes data in both the bars and spaces. It combines the pairs of digits into a single barcode character.
Widely used in the distribution and shipping industries.
Interleaved 2 of 5 is high density, 1D numeric barcode symbology that encodes any even number of numeric characters in the widths of the bars and spaces. This barcode symbology is called "interleaved" because the first numeric data is encoded in the first 5 bars while the second numeric data is encoded in the first 5 spaces (that separate the five bars). Thus the first five bars and spaces encode two characters.
Interleaved 2 of 5 barcode is same as standard 2 of 5 barcodes expect that it encode data in both i.e. bars and spaces of barcodes. This barcode symbology is primarily used in distribution and warehouse industry.
Interleaved 2 of 5 barcodes combine the pairs of digits into single character. Each character is comprised of five bar and space elements. The five bars of Interleaved 2 of 5 barcode represent the first digit of the pair, while the next five spaces represent second digit of the pair.
Interleaved 2 of 5 is one dimensional barcoding system that represents only numeric data. The digits in Interleaved 2 of 5 barcodes are represents in pairs. The first digit of the pair is encoded in five bars whereas the second digit is encoded in the adjacent five spaces. Interleaved 2 of 5 barcodes contain quiet zone, start character, encoded information, stop character and trailing quiet zone.
Interleaved 2 of 5 is continuous barcode symbology because it does not use inter character spaces. Since this bar coding systems encode only even number of digits, so a leading zero will be added to the front of the Interleaved 2 of 5 barcode can encode data in any of the following two conditions:
- If the encoded data contains an odd number of digits and check digits are not in use.
- If the encoded data contains an even number of digits and check digits are in use.

ISBN stands for International Standard Book Number. ISBN 13 barcode is a type of linear barcode that is used on book cover. It contains 5 digit supplemental code, which is usually, encodes the retail price.
Used on Books.
The ISBN (International Standard Book Number) is unique commercial book identifier based upon the 9 digits Standard Book Numbering (SBN) developed by Gorden Foster. ISBN 13 barcode is used to monitor data in book publishing industry. ISBN barcode was initially developed at a ten digital numbers for publishers. The 10-digit ISBN barcode was created by the International Organization for Standardization (ISO) and was published in 1970 as international standard ISO 2108 (9-digit SBN code was used in the United Kingdom until 1974.) Since In January 2007 the ISBN redefined from a 10-digit to 13-digit that is compatible with Bookland EAN13.
In ISBN 13, there are two barcodes - the main barcode is standard EAN13, which encodes the ISBN number. The second barcode stores the 'additional characters', which can be either 2 or 5 characters of extra data. ISBN 13 barcode symbology is used to encode the price of the book.
Occasionally, a book may appear without a printed ISBN if it is printed privately or the author does not follow the usual ISBN procedure; however, this can be rectified later. A similar numeric identifier, the International Standard Serial Number (ISSN), identifies periodical publications such as magazines.
The old ISBN 10 bar coding system was EAN13/UCC-13, with the first three digits being “978” OR “979” and 9 digits the ISBN number of the book (without the ISBN check digit). The final digit is the EAN/UCC calculated check digit. Since the introduction of the ISBN 13 system the first three digits have been assigned as part of the ISBN 13 number. The different parts can have different lengths and are usually separated by hyphens (-).
The ISBN number is either 10 or 13 digits long and consists of the following parts:
- GS1 Prefix, either 978 or 979.
- The country of origin or language code.
- The publisher number which is assigned by the national ISBN agency.
- The item number.
- The checksum character which ensures that each ISBN is valid.

ITF-14 barcode is 14 digit linear barcode symbology. ITF-14 barcode is used to identify outer cartons or packs of saleable items specified by major retailers and wholesalers.
Generally used to mark shipping cartons.
ITF-14 barcode is the GS1 implementation of an Interleaved 2 of 5 barcode symbology to encode a Global Trade Item Number. ITF-14 barcode is mainly used on packaging levels of a product, such as a case box of 24 cans of soup. The ITF-14 will always encode 14 digits. The ITF-14 barcode is used to create the shipping container symbol. This ITF-14 barcode is used to mark cartoons and palettes that are including goods with an EAN13 code. One digit is added in front of the EAN13 barcode to mark the packing variant.
ITF-14 barcode is 14 digit barcode symbology which is used to mark the external containers of the products with EAN identifier. It is based on the 2 of 5 barcode. The lines at the top and the bottom of the ITF14 code are called bearer bars and are used to prevent "short scan". Due to the structure of the Interleaved 2 of 5 barcode, it is statistically possible in some situations for a scanner to cut diagonally through only part of the code. The bearer bars disrupt the scan and insure that only complete scans will return a valid read. The bearer bars have another advantage when using the flexographic process to print barcodes directly on cartons. They provide extra physical support for the ends of the bars on the flexographic plate. Using a complete box also provides support for the ends of the bearer bars.
The ITF-14 barcode symbol is a composition of the barcode symbol used “interleaved 2 of 5” (Code 25 interleaved) and the 14 digit the length the container symbol. ITF is an abbreviation of “interleaved two of five”.
ITF-14 barcode symbology contains the following information:
- Digit 1 : Packing identifier
- Digits 2-3 : UPC numbering system or EAN prefix
- Digits 4-8 : Manufacturer identification number
- Digits 9-13 : Item identification number
- Digit 14 : Check Digit

LOGMARS stands for Logistics Applications of Automated Marking and Reading Symbols. It is primarily used in various barcoding labels, like name badges, inventory and other industrial applications.
Used in US government specification.
LOGMARS (Logistics Applications of Automated Marking and Reading System) is useful application of Code 39 (code 3 of 9) use by the US Department of Defense and is governed by the Military standard MIL-STD -1189B.The LOGMARS barcode symbol is a standard based on the code 39 symbology. LOGMARKS not only contains information about where the barcode must be placed on military shipment but also what information must be encoded into the barcode to fit military specifications. The LOGMARS military barcode is encoded in the Code 39 barcode type.
The character set of LOGMARS symbology consists of barcode symbols representing numbers 0-9, upper-case letters A-Z, the space character and the following symbols: - . $ / + %. Each character is composed of nine elements (binary value 0). The width ratio between narrow and wide can be chosen between 1:2 and 1:3.
Each character in LOGMARS consists of 9 elements: 5 bars and 4 spaces. Each character includes 3 wide and 6 narrow elements. Characters are separated by an inter-character gap which is the same width as a narrow bar. The ratio of wide: narrow bar width may be in the range of 1.8 to 3.4. Barcodes with a narrow bar width of less than 0.020 inches (0.508mm) should have a ratio of at least 2.5. A ratio of 3.0 is recommended. Every Code 39 barcode should be preceded and followed by a quiet zone the width of at least 10 narrow bars.
This barcode itself does not have a check digit but it can be considered self-checking on the grounds that a single erroneously interpreted bar cannot generate another valid character. LOGMARS does not require a checksum, although a modulo 43 check digit may be appended for increased data integrity (the Mod 43 checksum is seldom used). LOGMARS is just about the only type of barcode in common use that does not require a checksum. This makes it especially attractive for applications where it is inconvenient, difficult, or impossible to perform calculations each time a barcode is printed.

MSI is also known as Modified Plessey, is a linear barcode symbology developed by the MSI Data Corporation. It is continuous barcode symbology that is not self checking.
Widely used in library shelf tags and retail stores.
MSI (Also known as Modified Plessey) is a barcode symbology introduced by the MSI Data Corporation based on the original Plessey Code symbology. It is a continuous symbology that is not self-checking. MSI is used initially for inventory control, marking storage containers and shelves in warehouse environments. The Plessey code was primarily designed in England and gave rise to several variations including the MSI, Anker, and Telxon codes. Of these, the MSI Plessey is still in use in the USA; it is used in libraries, and is often used for retail grocery shelf marking.
The MSI Plessey barcode is a pulse-width modulated non-self checking barcode symbology. Each character is represented by 4 bars; a narrow bar represents a binary 0 and a wide bar represents a binary 1. The bars have the binary weights 8-4-2-1. It is possible to encode the digits 0 through 9 and the letters A through F, although this code is most often used just for numeric information. The start character is a single wide bar, and the stop character is two narrow bars.
The MSI character set consist of the numbers 0-9 as well as two "guard" characters (representing the beginning and end of the barcode). The symbology does not support alphabetic characters. Each digit and guard character is represented by a binary number. This barcode symbology can be read in either direction (left to right or right to left).
MSI Plessey barcode encodes hexadecimal digits (i.e., the hex digits 0-F) as 4 bars (bits). The LSB (Least significant bit) is on the first bar on the left, and the MSB (Most significant bit) is the last bar on the right. A "0" bit is represented as a narrow bar, followed by a wide space. The "1" is represented by a wide bar, followed by a narrow space.
MSI Plessey barcode comprises:
- The forward start code
- The label / data digits
- The check code, for error detection
- The termination bar
- The reverse start code
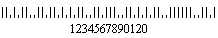
Planet stands for Postal Alpha Numeric Encoding Technique. Planet barcode is used in post office to identify and track pieces of mails during their delivery.
Used to encode ZIP codes on US mail.
PLANET code (The Postal Alpha Numeric Encoding Technique) is one dimensional barcode symbology that are used by the United States Postal Service to identify and track pieces of mail during their delivery. The PLANET codes are either 12 or 14 digits long. The US post office uses a combination of two tracking numbers (The Postnet code and planet) to track customer’s piece of mail. PLANET barcode is inverse of the POSTNET barcodes.
Like POSTNET, PLANET barcodes also encode data in half and full-height bars. This 1D barcode symbology always starts and ends with a full bar (often called a guard rail) and each individual digit is represented by a set of five bars. In PLANET barcodes, the two bars (out of 5 bars) are the short bar.
Planet barcode:
- Identifies mailpiece class and shape.
- Identifies the Confirm Subscriber ID.
- Containn up to 6 digits of additional information that the Confirm subscriber chooses, such as a mailing number, mailing campaign ID or customer ID.
- Ends with a check digit.
PLANET (USPS PLANET) Code comprises the following elements:
- Service Type ID : The first 2 digits signify the services and the class/shape of the mail.
- Subscriber ID : The next 5 digits identify the subscriber (allotted by the Postal Service).
- Mailing ID : The next 4 or 6 digits are available to the mailer to use for their own identification purposes (e.g., mailings, clients, etc).
- Check-Sum Digit : The 12th or 14th digit is a check-sum digit that helps the Postal Service to detect errors.
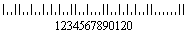
Postnet stands for Postal Numeric Encoding Technique. Postnet barcode starts and ends with a full bar (often called a guard rail or frame bar).
Used to encode ZIP codes on US mail.
Postnet barcode was developed by the united state postal service to allow faster sorting and routing of mail. Unlike most other barcodes in which data is encoded in the width of the bars and spaces, PostNet code is 1D barcode that encodes data in the height of the bars. That is why when you look at the barcode all the bars are essentially the same width but vary only in height. The barcode itself can encode a standard 5-digit Zip Code, a Zip+4 code, or a full 11-point delivery point code.
The barcode starts and ends with a full bar (often called a guard rail or frame bar and represented as the letter "S" in one version of the USPS TrueType Font). Each individual digit is represented by a set of five bars, two of which are full bars (i.e. two-out-of-five code). The full bars represent "on" bits in a pseudo-binary code in which the places represent, from left to right: 7, 4, 2, 1, 0.
This 1 D Post net barcode is replaced by the Intelligent Mail barcode which combines entire previous Postal Service barcodes and marking into a single barcode. The initial transition between the two barcodes includes the use of the Intelligent Mail Barcode by the USPS and requirements that it be used to receive automation discount rates. The Intelligent Mail Barcode was initially supposed to be required beginning May 2011 however the USPS postponed the requirement date, allowing mailers to continue receiving automation discount rates using the Postnet Barcode after the May 2011 deadline. As the transition between barcodes continues, regular mail that includes Postnet Barcode will still be accepted by the USPS.
Encoding:
Post Net code is one dimesnional bar coding system that contains full and half bars. Each bar represents a binary value (0 or 1), and 5 bars together form a single character. The number "1" represents a "tall" bar, whereas a "0" represents a "half" bar. The numbers "10010" would represent a full bar followed by two half bars followed by a full bar and a final half bar.

Standard 2 of 5 is linear barcode symbology that encodes data in the width of the bars. Is can be used in photofinishing, airline tickets making and warehouse sorting industries.
Primarily used for warehousing and airline ticket marking.
Stanadard 2 of 5 is low density 1D barcode symbology that was created in 1960. This is called "2 of 5" due to the fact that digits are encoded within the 5 bars. In the five bars the 2 of which are wide and remaining three are narrow. Since the standard 2-of-5 is numeric barcode symbology, its character set must includes 10 digit characters (0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
Standard 2 of 5 barcode must include start/stop character and ends with modulo 10 check digit. This bar coding systems encodes information in the bars, whereas the spaces are fixed width and used to separate the bars. It is most widely used in warehousing industry, photofinishing and airline ticket marking.
Structure of Standard 2 of 5 barcode:
- Start character
- Data encoded
- Optional Mod 10 check digit
- Stop character
Standard 2 of 5 is 1 D barcoding system that encodes information in the width of the bars. The major advantage of Standard 2-of-5 barcode over the other barcode symbologies is that it can encode any number of numeric values.

Telepen barcode symbology encodes full ASCII character set. Telepen barcode has 2 different types of modes i.e. alphanumeric mode and numeric only mode.
Used to encode ZIP codes on US mail.
Telepen barcode introduced in 1972 in the UK to express all 128 ASCII characters without using shift characters for code switching and using only two different widths for bars and spaces. Telepen is 1D barcode symbology represents the full ASCII character set without shift characters. It is extremely secure as it has negligible risk of misreads, has a double density numeric only mode and is supported by most leading barcode reader manufacturers.
Unlike most of the one dimensional barcode symbologies, Telepen barcode does not define independent encodings for each character, but instead operates on a stream of bits. It is able to represent any bit stream containing an even number of 0 bits, and is applied to ASCII bytes with even parity, which satisfy that rule. Bytes are encoded in little endian bit order.
In Telepen barcode the string of bits is divided into 1 bits, and blocks of the form 01*0. That is, blocks beginning an ending with a 0 bit with any number of 1 bits in between.
These are then encoded as follows:
- "1" is encoded as narrow bar-narrow space
- "00" is encoded as wide bar-narrow space
- "010" is encoded as wide bar-wide space
Otherwise, the leading "01" and trailing "10" are both encoded as narrow bar-wide space, with additional 1 bits in between coded as described above. Wide elements are 3 times the width of narrow elements, so every bit occupies 2 narrow elements of space.
Telepen barcodes always start with ASCII _ (underscore). This has code 0x5F, so the bit stream is 11111010. Thus, it is represented as 5 narrow bar/narrow space pairs followed by a wide bar/wide space.

UCC/EAN-128 barcode is variant of code 128. There are two main components of UCC/EAN-128 barcode the data with its Application Identifier and the barcode symbology used to encode the data.
Widely used in industry.
UCC/EAN-128 barcode symbology is also known as EAN-128, UCC-128, USS-128, GS1-128, GTIN-128, UCC-12, EAN/UCC-13, EAN/UCC-14. UCC/EAN-128 barcode was introduced to provide worldwide format and standard for exchanging common data between companies. While other barcodes simply encode data with no respect for what the data represents, GS1-128 encodes data and encodes what that data represents.
UCC/EAN-128 is 1D barcode symbology that encode one or more AI to specify that what type of data is encoded. The Application Identifier is a 2, 3, or 4-digit number that identifies the type of data which follows. By convention, the Application Identifier is enclosed in parentheses when printed below the barcode (the parentheses are only for visual clarity, and are not encoded in the barcode). In most of cases, application identifier also decides the length of the data and the format of the data. When barcode scanner read Code 128 barcode with a leading FNC1 character, the next 2-4 digits will represent the applicable AI.
UCC/EAN-128 is itself not only one dimensional barcode symbology, but also it is standard that defines both the kind of data and its format. UCC/EAN-128 code is derivative language of the Code 128 barcode symbology that contains flagging character, Function Code 1 (FNC1) and application identifiers.
FNC1 is also used to separate fields in UCC / EAN-128 barcodes. To insert the field separator FNC1 in your barcodes, use the % (percentage) character in your message and specify optional format 1.
UCC/EAN-128 barcode structure:
As mentioned above, a UCC/EAN-128 barcode is, in fact, Code 128 barcode. The UCC/EAN-128 barcoding system has the following Code 128 structure:
- Code-128 Start character (A, B, or C).
- Code-128 FNC1 character (character 102).
- Application Identifier (from AI table corresponding to data to be encoded).
- Data to be encoded (format depends on Application identifier).
- A Code-128 checksum character.

UPCA barcode is linear barcode symbology that has 12 digit code. UPCA barcode is used for marking products which are sold at retail in USA.
Used to encode ZIP codes on US mail.
UPC stands for Universal Product Code. UPC barcodes were initially introduced to help grocery stores to speed up the checkout process and keep better track of inventory product. The most common form the UPCA barcode symbology is widely used in North America, UK, Australia and New Zealand for tracking retail items details. This 1D bar coding system identifies the manufacturer and its specific product so point of sale cash register systems can automatically look up the price.
UPCA barcode contains 12 numerical digits, which are uniquely assigned to each trade item. Along with the related EAN barcode, the UPC is the only barcode that allowed for scanning trade items at the point of sale per GS1 standards. UPC data structures are a component of GTINs (Global Trade Item Numbers). All of these data structures follow the global GS1 standards.
UPCA barcode has a scannable strip of black bars and white spaces, above a sequence of 12 numerical digits. No letters, characters or other content of any kind may appear on a standard UPCA barcode. The digits and bars maintain a one-to-one correspondence. In other words, there is only one way to represent each 12-digit number visually and there is only one way to represent each visual barcode numerically.
The scannable area of UPCA barcode follows the pattern SLLLLLLMRRRRRRE, where the S (start), M (middle) and E (end) guard bars are represented exactly the same on every UPC and the L (left) and R (right) sections collectively represent the 12 numerical digits that make each UPC unique. The first digit L is the prefix. The last digit R is an error correcting check digit, allowing some errors in scanning or manual entry to be detected. The non-numerical identifiers, the guard bars, separate the two groups of six digits and establish the timing.

UPCE barcode is variation of UPCA barcode. UPCE barcode is also known as the zero suppression versions and encodes 12 digits product codes.
Retail industry in the U.S. and Canada.
UPC code is 1D barcode symbology that primary used in retail industry to identify particular product, so that the cash registers system automatically lookup the data. UPC (Universal Product Code) barcodes are used on those small packages where a full 12-digit barcode may not fit. A 'zero-compressed' version of UPC was introduced called as UPCE. This one dimensional bar coding system uses 6-digits code and does not use middle guard bars.
UPCE is a variation of the UPCA barcode that is used for number system 0. UPCE barcodes can be printed in a very small space and are used for labeling small items. UPCE barcodes consist of the first three characters of the manufacturer code, the last two characters of the product code, followed by digit “3”. In UPCE barcodes the product code can only contain two digits (00000 to 00099).
There are two types of UPC barcode:
- UPCA
- UPCE
UPCE barcode has the following structure:
- Start guard bars, always with a pattern bar+space+bar.
- Left halve, five digits calculated from the equivalent UPC number.
- Check digit.
- Stop guard bars, always with a pattern bar+space+bar.

USPS Sack Label barcode symbology is also known as USPS 25 Sack Label. USPS Sack Label encodes 8 digits i.e. 5 digits Zip Code and 3 digit content identifier number (CIN).
Used by United States Postal Services.
USPS Sack Label is 1D barcode symbology that is used by United States Postal Services (USPS) for labeling of postal sacks; for automation rate mailings; for periodicals and standard mail (letter size & flat size pieces). USPS Sack Label barcode is also known as USPS 25 Sack Label. USPS Sack Label barcode is same as Interleaved 2 of 5 barcode which encodes 8 digits i.e 5 digit Zip Code (the sack destination) and 3 digit content identifier number (CIN).
USPS sack label barcode represent the following information: the 5-digit ZIP Code destination of the sack and the 3-digit content identifier number (CIN) that is applicable to the content of the sack. This one dimensional bar coding system contains the "ZIP code" of the receiver and a "Content Identifier Number". The maximum length of USPS sack label barcode is 0.980 inch.
USPS sack label barcode has the following structure:
- 5 digits for "ZIP code"
- 3 digits for "Content Identifier Number" [CIN].
The "Content Identifier Number" [CIN] contain information about:
- Mailing class (express, priority, first-class, periodicals, standard, package)
- Presorting / automation process
- Sack

USPS tray label barcode is linear barcode symbology that is used in United States Postal Services (USPS) to label postal trays, automation rate mailings, periodicals and standard mails.
Used by United States Postal Services.
Tray Label is used by United States Postal Services (USPS) for labeling of postal trays, automation rate mailings, periodicals and standard mail (letter size & flat size pieces). USPS Tray Label barcode symbology is in fact Interleaved 2 of 5 symbology with exactly 10 digits encoded: 5-digit Zip Code (the tray destination) and a 3-digit content identifier number (CIN), and a 2-digit USPS processing code.
USPS tray label contains the “ZIP code” of the receiver and a “Content Identifier Number”.
The value to encode length is fixed to 10 digits and it must have the following structure:
- 5 digits for "ZIP code".
- 3 digits for "Content Identifier Number" [CIN].
- 2 digits for "Processing Code".
The "Content Identifier Number" [CIN] indicates this information:
- Mailing class (express, priority, first-class, periodicals, standard, package)
- Presorting / automation process
- Tray
The "Processing code" indicates this information:
- 07 = other

USS-93 is variable length, alphanumeric linear barcode symbology. USS-93 barcode is used in Canada post office to encode the supplementary delivering information.
Primarily used in postal services.
USS-93 is high density and alpha numeric barcode symbology, developed by Intermec in 1982. USS-93 barcode is improvement over the Code 39 barcode and provides higher information density for alphanumeric data. This barcode symbology can represent the full ASCII character set by using combinations of 2 characters. USS-93 barcode can encode 47 characters. The character set of this barcode symbology includes digits (0-9), uppercase letters and special characters ($, %, /, +). USS-93 barcode is used in Canada post office to encode extra delivery information.
USS-93 is continuous and 1D barcode symbology that encodes all 128 full ASCII characters and produce denser code. Within the USS93 barcode, the characters are divided into nine modules. This barcoding system has three bars and spaces. USS-93 barcodes define 5 special characters (including start and stop character), which can be combined with other characters to represent all 128 ASCII characters. USS-93 barcode symbology is also known as Code 93, Code 9/3, Code 93 Extended, USD-3, USS-93, Code 9/3, USS-93, Code 93 and Code 93 Full ASCII.
USS-93 barcode include two check characters which "C" and "K". These two check characters follow the encoded data itself. The "C" checksum character is modulo 47 remainder of the sum of weighted value. The weighting value starts from "1" for the right most data character, 2 for the second to last, 3 for the third-to-last and so on, up to 20. After 20, the sequence wraps around back to 1.
Structure of USS-93 barcode:
- Start character (*)
- Encoded data
- First modulo-47 check character ‘C’
- Second modulo-47 check character ‘K’
- Stop character (*)
- Termination bar